Description of the problem
Anomaly detection is a process of detecting outliers in the data. The applications of anomaly detection includes detecting credit card fraud and spam emails. The data you will be analyzing consists of 'normal' applications and 'risky' applications for a credit card. You will use two models, called One-Class Support and Robust Covariance Estimation, to distinguish between those two classes. Unlike supervised training, the scores generated by the models only indicate a measure of distance from the 'normal' category of data. The scores can be used as the threshold for detection, not for probabilities.
The training data consists of 1,000 credit card applications with 20 feature columns and 1 label column. (Data source: UCI data repository)
Parameter | Description | Parameter | Description |
status_acc | Status of existing checking account (categorical) A11 : ...< 0 DM A12 : 0<=...< 200 DM A13 : ...>= 200 DM / salary assignments for at least 1 year A14 : no checking account | property | (categorical) A121 : real estate A122 : if not A121 : building society savings agreement/ life insurance A123 : if not A121/A122 : car or other, not in attribute 6 A124 : unknown / no property |
duration | Duration in month (numerical) | age | Age in years (numerical) |
credit_history | (categorical) A30 : no credits taken/ all credits paid back duly A31 : all credits at this bank paid back duly A32 : existing credits paid back duly till now A33 : delay in paying off in the past A34 : critical account/ other credits existing (not at this bank) | inst_plans | Other installment plans (categorical) A141 : bank A142 : stores A143 : none |
purpose | (categorical) A40 : car (new) A41 : car (used) A42 : furniture/equipment A43 : radio/television A44 : domestic appliances A45 : repairs A46 : education A47 : (vacation - does not exist?) A48 : retraining A49 : business A410 : others | housing | (categorical) A151 : rent A152 : own A153 : for free |
amount | Credit amount (numerical) | num_credits | Number of existing credits at the bank (numerical) |
saving_acc | Savings account/bonds (categorical) A61 : ... < 100 DM A62 : 100 <= ... < 500 DM A63 : 500 <= ... < 1000 DM A64 : .. >= 1000 DM A65 : unknown/ no savings account | job | (categorical) A171 : unemployed/ unskilled - non-resident A172 : unskilled - resident A173 : skilled employee / official A174 : management/ self-employed/ highly qualified employee/ officer |
present_emp_since | Present employment since (categorical) A71 : unemployed A72 : ... < 1 year A73 : 1 <= ... < 4 years A74 : 4 <= ... < 7 years A75 : .. >= 7 years | dependents | Number of people being liable to provide maintenance for (numerical) |
inst_rate | Installment rate in percentage of disposable income (numerical) | telephone | (categorical) A191 : none A192 : yes, registered under the customers' name |
personal_status | Personal status and sex (categorical) A91 : male : divorced/separated A92 : female : divorced/separated/married A93 : male : single A94 : male : married/widowed A95 : female : single | foreign_worker | (categorical) A201 : yes A202 : no |
other_debtors | Other debtors/ guarantors (categorical) Other debtors / guarantors A101 : none A102 : co-applicant A103 : guarantor | label | (target) 1 : Good 2 : Bad |
residing_since | Present residence since (numerical) |
What you will build
- One-Class SVM anomaly detector
- Robust Covariance Estimation
What you will learn
- Explore the dataset by using pandas, numpy, matplotlib.
- Split dataset into train, test and validation sets by using stratified sampling.
- One-Class Support Vector Machine based anomaly detector.
- Robust Covariance Estimation for detecting outliers in a Gaussian distributed dataset.
- pandas
- numpy
- matplotlib
- sklearn
Since the original dataset does not have column names, remember to initialize the column names before next step. The dataset contains 8 numeric variables and 13 categorical variables.
Now check again the variables, are they all meaningful for the model? You can drop the variable that you think will not help you build the detector.
In the following steps, we will be using One-Class SVM predict function in sklearn to generate the output. It will return +1 or -1 to indicate whether the data is an "inlier" or "outlier" respectively. To make the label value unified, it is better to replace label [1, 2] with [1, -1]. This also transforms our data from multi-class (multiple different labels) to one-class (boolean label), which is necessary when using One-Class SVM.
After cleaning the data, the top 5 rows in the dataset (part of the columns) should be like this:
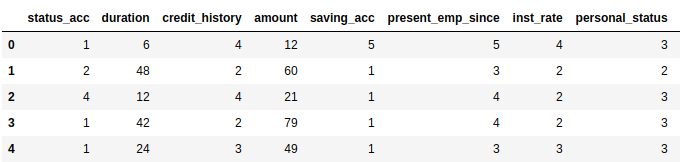
In this step, we need to split the data several times for different use.
- Split the data into "normal" transactions label_normal (label=1) and "risky" transaction label_risky (label=-1) for future evaluation.
- Split the data into training (80%) and test (20%) using stratified sampling for modeling.
- Split the features and labels into X_train, X_test, y_train and y_test.
- Select rows containing "normal" transactions X_train_normal from train set to train the detector.
- Split the train set into training (80%) and validation (20%) sets using stratified sampling for hyperparameter tuning
- Select rows containing "normal" transactions X_training_normal from training set.
One-Class Support Vector Machine (SVM) is a binary classifier where the training data has examples of only one class (normal data). The model separates the collection of training data from the origin by using maximum margin.
First, you need to tune the hyperparameters. You can specify a grid of value for each of the parameters. Then, use the training data which consists of examples from a single class to fit an untrained model, and optimize the scores (F-score, recall, precision, AUC), using validation data which consists of examples from both classes. Finally, you will find the best settings for the model.
For One-Class SVM, parameters ‘tol' (Tolerance for stopping criterion) and ‘nu' (an upper bound on the fraction of training errors and a lower bound of the fraction of support vectors) can be used to tune the model.
Since our goal is to detect anomaly data where label=-1, it is important to optimize F-score and and the recall. Let's select the parameter set {nu:0.01, tol:0.01}, with highest recall score of label= -1 and good F1 score(say at least 0.4). The performance result shows below:
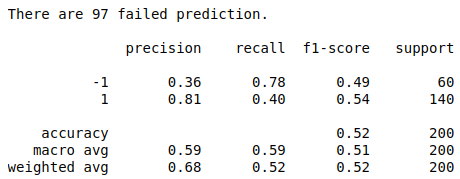
Another way to perform outlier detection is to assume that the regular data come from a known distribution; For example, data are Gaussian distributed. From this assumption, we can try to define the "shape" of the data to define outlying observation as observations which stand far enough from the fit shape. [2]
The sklearn provides an object covariance.EllipticEnvelope that fits a robust covariance estimate to the data, and thus fits an ellipse to the central data points, ignoring points outside the central mode.
Before building the model, the first thing you need to do is hyperparameter tuning. For EllipticEnvelope, you can try to find the best value of ‘contamination' ( The amount of contamination of the data set) to tune the model.
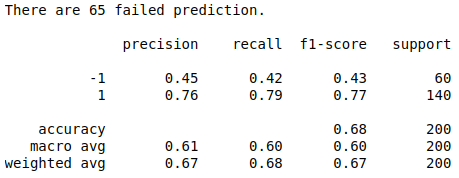
As we explained in the previous step, you need to find a model which has a high F-score and recall score. In the notebook, select parameter contamination=0.17 to build the model. The performance of the model is shown below:
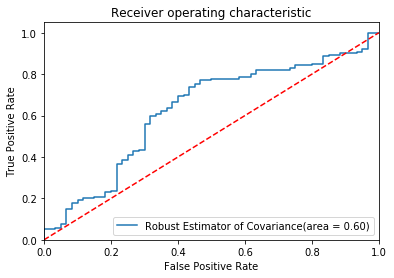
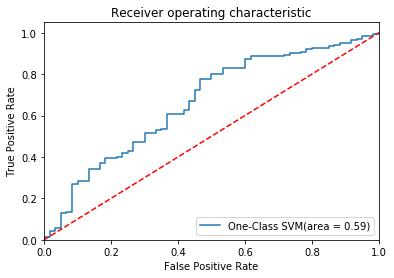
To visualize the performance, you can plot the ROC curve of two models in one plot. 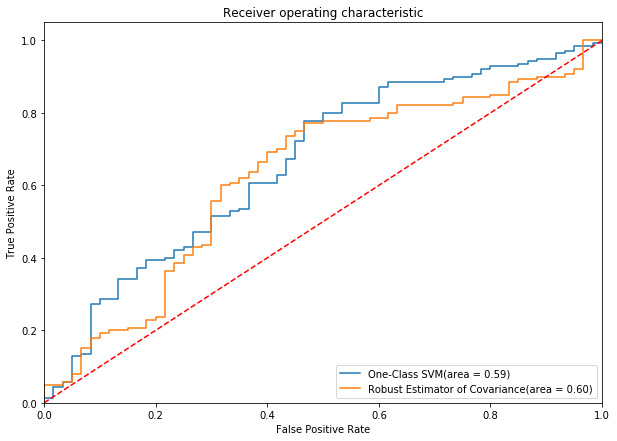
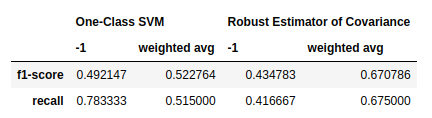
Area under the ROC curve provides a good way to measure the discriminatory power of the anomaly detectors. Based on the graph, we can learn that the One-Class SVM and Robust Estimator of Covariance have comparable performance in anomaly detection. In terms of -1 label detection, you can see from the table below that One-Class SVM does a much better job with recall score of -1 0.78.
Result table
- Azure ML Team for Microsoft. (2014, September 2). Anomaly Detection: Credit Risk.
- Scikit Learn. 2.7. Novelty and Outlier Detection.