Description of the problem
Lending Club strives to connect borrowers with investors through our online marketplace.
The goal is to predict the interest rates that Lending Club should use, based on previous borrowers data they have. Whether or not a client will repay a loan or have difficulty is a critical business need. In this project, we are going to see some models that the machine learning community can develop to help organizations like Lending Club.
What you will build
- Machine learning models to predict interest rates.
What you will learn
- Module 2: Clustering analysis and building machine learning models
The experimentation will be done in Jupyter Notebooks, primarily in Python3.6.
- pandas
- numpy
- matplotlib
- seaborn
- scipy
- sklearn
In this project, we are going to use the same Lending Club loan dataset as in the previous module. The provided file is a cleaned version of the original Lending Club dataset available at Kaggle. The files provided includes a file containing the description of the features, LCDataDictionary, and the data file named LendingClubLoan.csv.
The original version of the dataset is about 230mb. The version provided is a subset of 9999 samples of the cleaned dataset. Let us first take a look at some of the features in the given dataset. The entire list can be found in the jupyter notebook.
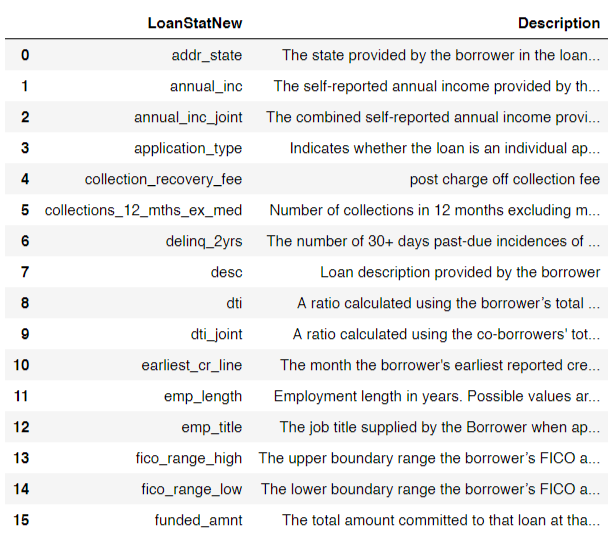
Here is a look at some of the entries in the dataset:
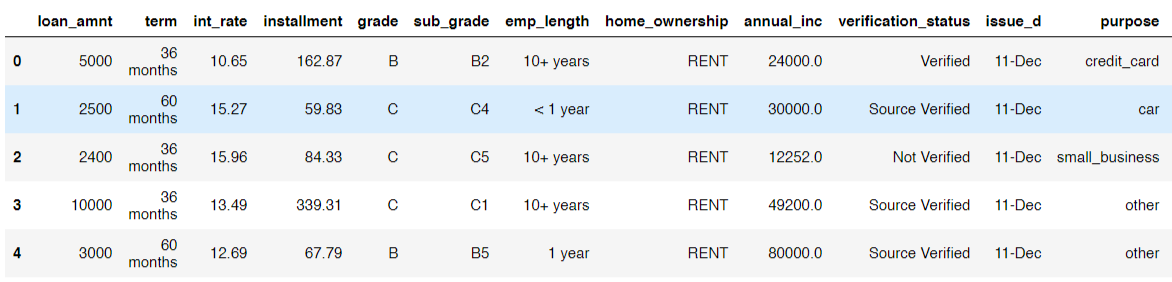
.
We use various metrics to judge model performance. Some of the metrics we will be using are:
Root Mean Squared Error
It represents the sample standard deviation of the differences between predicted values and observed values.
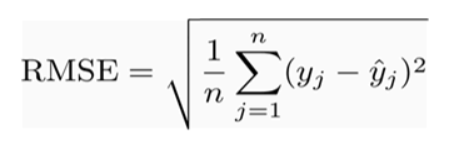
Mean Absolute Error
MAE is the average of the absolute difference between the predicted values and observed value. The MAE is a linear score which means that all the individual differences are weighted equally in the average.
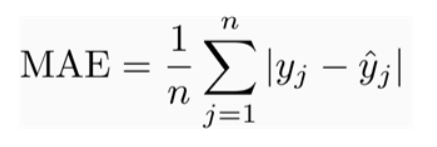
Mean Absolute Percent Error
MAPE measures the size of the error in percentage terms. It is calculated as the average of the unsigned percentage error.
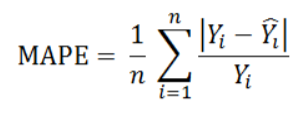
We will preprocess the data for ease of calculations and better convergence of the models while training. THe three major operations we will carry out are:
- Normalising the data.
- Randomizing the data
- Test-Train (20:80) split of the data.
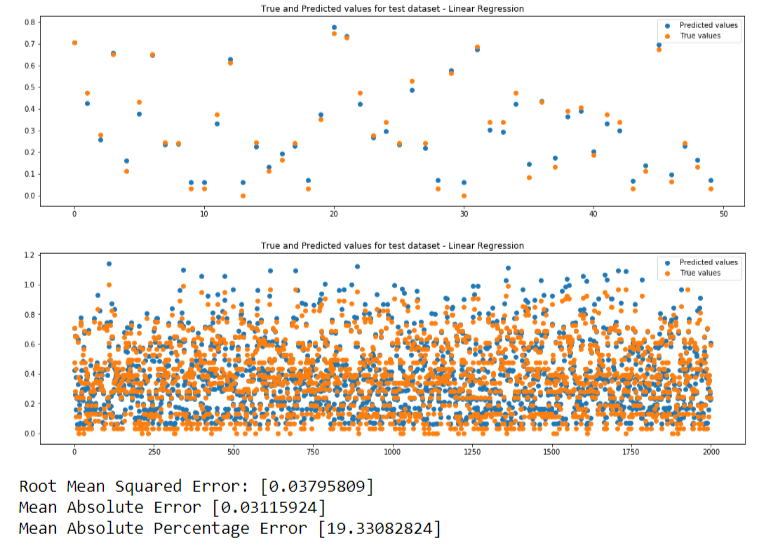
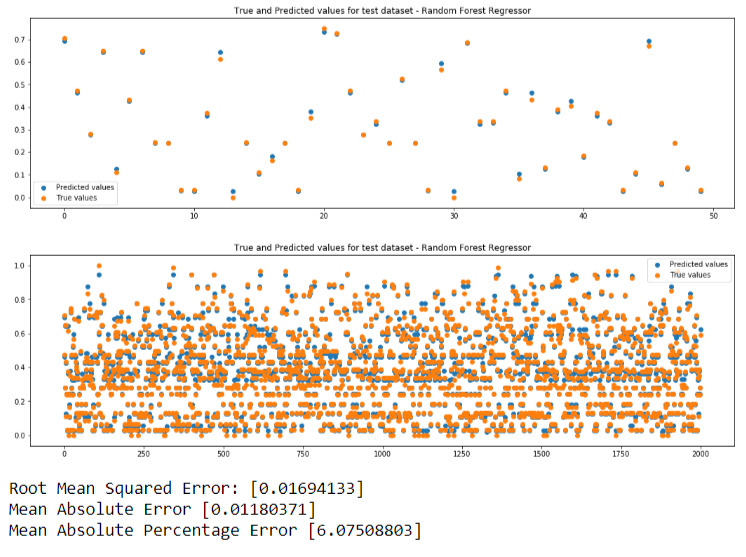
We will be performing predictions so we need regression models.We will be using 3 machine learning models. If predicted value is same as true value, the points in the plots will be overlapping. Closer the points, better is the prediction.
- Linear Regression
- Random Forest Regression
- Neural Network - Multilayer Perceptron
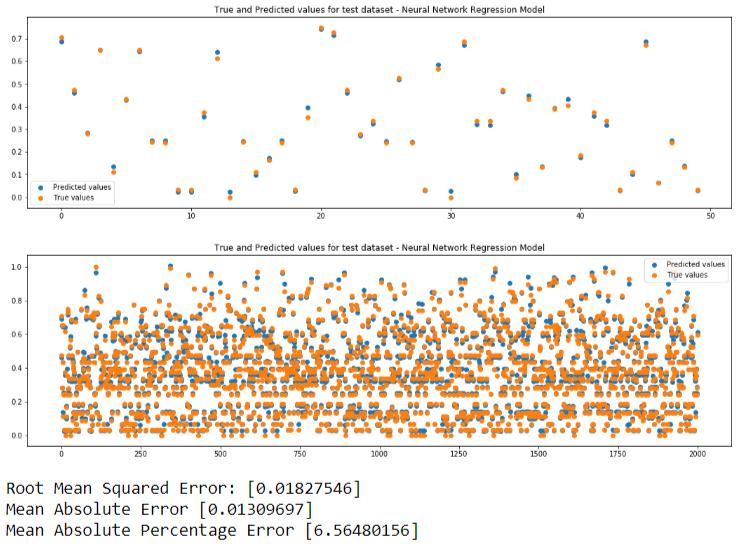
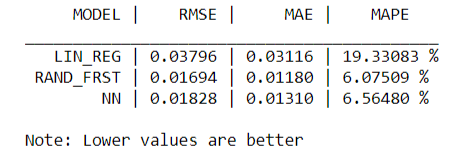
Here is a comparison of the metrics from the 3 models:
To save a model for future use, one way is to use the pickle module provided by python. It saves a python object as a file and can be imported later into another program. We will use the pickled models from this lab in our next lab.
We can use this trained model to predict the interest rates for new data.