Description of the problem
In the lending industry, investors provide loans to borrowers in exchange for the promise of repayment with interest. If the borrower repays the loan, then the lender profits from the interest. However, if the borrower is unable to repay the loan, then the lender loses money. Therefore, lenders would like to minimize the risk of a borrower being unable to repay a loan.
In this exercise, we will use publicly available data from LendingClub, a website that connects borrowers and investors over the internet.
The dataset is in the file LoansStats3a.csv. There are 42,535 observations, where 31,534 are representing 3-year loans and 11,001 are representing 5-year loans that were founded through the LendingClub.com platform. Notes in the dataset offered by Prospectus.
We will use this dataset to predict whether or not the customer can pay for the loan on time. In this project, we are going to see sort of models the machine learning community can develop.
What you will build
- Logistic regression classifier
- Random forest classifier
- Multi-layer perceptron classifier
What you will learn
- Perform exploratory data analysis (EDA) on data
- Clean the data for fitting the model
- Use models in sklearn to build, train data and evaluate their performance
- pandas
- numpy
- matplotlib
- seaborn
- sklearn
- scipy
- joblib
- pickle
- json
First, use pandas pd.read_csv to read the csv file. First, take a look at the dataset.
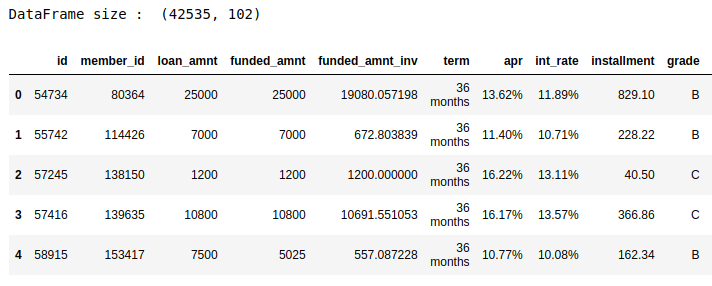

The dataset is 32.8MB with 42,535 rows and 102 columns. Most variables are numeric and there are also 26 categorical variables. It is all the information about each loan application at LendingClub between 2007 and 2011. Every loan has its own row and is identified by the feature member_id.
How to predict whether or not the customer can pay for the loan on time?
Let us take a look at the "loan_status" column:
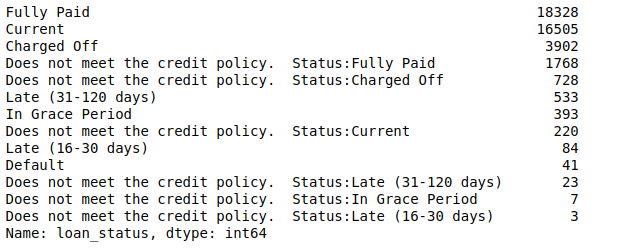
In this project, we use [ "Late (16-30 days)", "Late (31-120 days)", "Default", "Charged Off"] as bad_indicators.
You can plot the density plot for loan_amt distribution
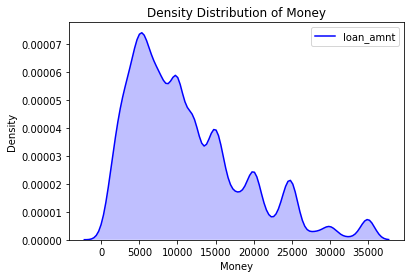
The plot shows that the right-skewed nature of laon_amnt distribution implies people tend to borrow on higher side.
Now, try to draw a pair plot to identify trends for follow-up analysis. A pairs plot allows us to see both distribution of single variables and relationships between two variables.
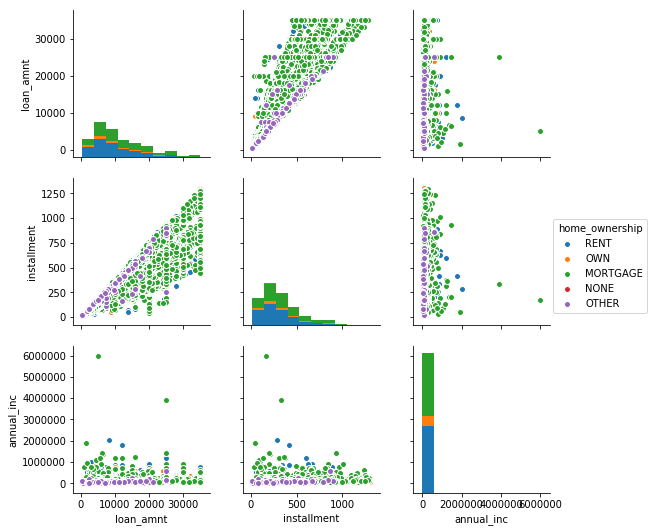
As we can see, there no correlation between loan_amnt and annual_inc, however there does exist an obvious correlation between loan_amnt and installments.
First, you need to drop off the loans which have more than two missing values and select the loan which are before 2013.
Then, create custom features. In this project, we use ['fico_range_low', 'fico_range_high', 'inq_last_6mths', 'home_ownership_num', 'annual_inc', 'loan_amnt'] as the features, where 'home_ownership_num' is the label encoded 'home_ownership'.
Now, your dataset should be like this:
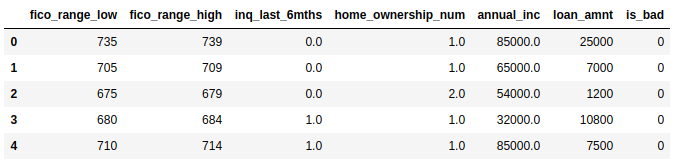
Set ‘is_bad' as your target and others as predictors, then use 80% of the dataset as training data.
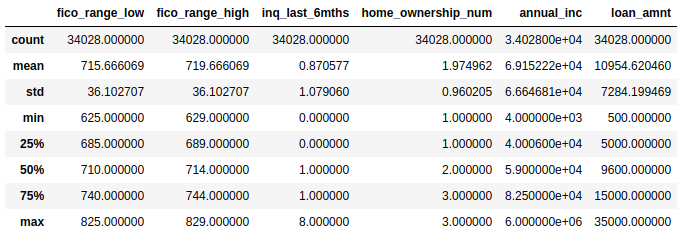
The description of training set should be like this.
Before making the prediction, you can define several functions to help you do the analysis.
Here are the functions in our notebook:
Function | Description |
buildModel |
|
makePrediction |
|
calcAccuracy |
|
calculate_score |
|
cal_credit |
|
runAnalysis |
|
Logistic Regression Classifier | |||
Accuracy score | 0.92 | Precision score | 0.85 |
Recall score | 0.92 | F1-score | 0.89 |
Mean accuracy (CV) | 0.88 |
Logistic Regression Classifier | |||
Accuracy score | 0.90 | Precision score | 0.86 |
Recall score | 0.90 | F1-score | 0.88 |
Mean accuracy (CV) | 0.87 |
Logistic Regression Classifier | |||
Accuracy score | 0.92 | Precision score | 0.85 |
Recall score | 0.92 | F1-score | 0.89 |
Mean accuracy (CV) | 0.88 |
Result table
