Description of the problem
EDGAR is the Electronic Data Gathering, Analysis, and Retrieval system used at the U.S. Securities and Exchange Commission (SEC). It is the primary system for submissions by companies and others who are required by law to file information with the SEC. With millions of companies and individuals filing, EDGAR provides efficiency and transparency and fairness of the securities markets.
In this project, we will perform a sentiment analysis on data sourced from EDGAR. Sentiment analysis computationally identifies and categorizing opinions expressed in a piece of text to determine whether the writer or speaker's sentiment towards a particular topic is positive, negative, or neutral. The data you will be analyzing is the company earnings call transcripts. Sentiment analysis will be applied to each paragraph of the dialogues and it will return either a sentiment label or a sentiment score or both. In this analysis, several different Natural Language Processing (NLP) APIs will be introduced to compare the performances. The APIs used here are Amazon Comprehend, Microsoft Azure, Google Cloud, and IBM Watson. You will start off designing a crawler and preprocessing to prepare the data to be analyzed.
What you will build
- Web crawler and preprocessing function with BeautifulSoup, requests, and boto3
- Sentiment analysis with Amazon Comprehend, Microsoft Azure, Google Cloud and custom tuned TF-Hub and BERT models
What you will learn
- Design a web crawler based on the source code of a specific web by using BeautifulSoup and requests, and store the data in the expected structure.
- Conduct sentiment analysis by calling different APIs and visualize the results.
- Interact with Amazon S3 to download and upload the dataset and the final results to better maintain the data.
- Introduction to BERT model and how to use it to conduct sentiment analysis
- configparser
- boto3
- botocore
- beautifulsoup4
- requests
- pandas
- lxml
- matplotlib
- google-cloud-language
- google-cloud-storage
- watson-developer-cloud
Open the ‘crawler_425' folder, and you will see a Python script named ‘425_crawler.py'. This is the code for crawling the Earnings call transcripts from Edgar website. Inside the program, you will find 5 defined functions and a main function. In the main function, you will know how these 5 functions work together to implement the crawler.
if __name__ == '__main__':
cik, accessionNum, accessKey, secretAccessKey, location = parse_config()
s3_client = verify_aws(accessKey, secretAccessKey, location)
url_425 = get_url(cik, accessionNum)
csv_filename = fetch_and_write(url_425)
upload_to_s3(csv_filename, s3_client)Above is a function for each step of the crawler:
- Parsing the parameters which decide the specific call transcript file we want to crawl (CIK and Accession Number) and Amazon credentials (Access Key, Secret Access Key and Region Name) from a configuration file or the environment.
- Connecting to S3 by creating a boto3 client instance and testing the connection by calling client.list_buckets().
- Generating the URL to the website that contains the call transcript information.
- Fetching the text in the website and write into a csv file.
- Uploading the csv generated in the last step to S3.
Open ‘425_pre_processing' folder. There is a Python script called ‘Pre_processing.py' in the folder. Similar to the crawling phase, data preprocessing requires the following 4 functions to clean the data.
if __name__ == '__main__':
s3_resource, s3_client = connect_to_s3()
download_from_s3(s3_resource)
output_file = pre_processing()
upload_to_s3(output_file, s3_client)The codes above show every step in the data preprocessing phase:
- Connecting to S3 by creating a boto3 client instance and testing the connection by calling client.list_buckets().
- Downloading the raw data (csv file generated in the last phase) from S3 for preprocessing.
- Handling invalid characters and encoding problems in the csv file. Filtering the useless text in the csv file as well since we do not want to do analysis on those information such as date, name, and location. Then, write the cleaned data into a new csv file.
- Uploading the cleaned data to S3 for sentiment analysis.
As mentioned above, the text data you will be analyzing is the earning call transcripts file. Sentiment analysis will be applied to each paragraph of the dialogues and it will return either a sentiment label or a sentiment score or both.
Example: In this example, a customer mentions a pair of shoes he or she ordered. The API identifies the sentiment expressed by the customer along with a confidence score.
Sample Text: "I ordered a small and expected it to fit just right but it was a little bit more like a medium-large. It was great quality. It's a lighter brown than pictured but fairly close. Would be ten times better if it was lined with cotton or wool on the inside."
Connect to Amazon Comprehend API
Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents without the need of any special preprocessing. Amazon Comprehend processes any text files in UTF-8 format. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. With Amazon Comprehend you can search social networking feeds for mentions of products, scan an entire document repository for key phrases, or determine the topics contained in a set of documents.
(Image reference: https://aws.amazon.com/comprehend/)
Detect sentiment in the text
The Sentiment Analysis API returns the overall sentiment of a text (Positive, Negative, Neutral, or Mixed). It returns the probability for each class which adds up to 1. This is an example response from the API.
{
"SentimentScore": {
"Mixed": 0.030585512690246105,
"Positive": 0.94992071056365967,
"Neutral": 0.0141543131828308,
"Negative": 0.00893945890665054
},
"Sentiment": "POSITIVE",
"LanguageCode": "en"
}
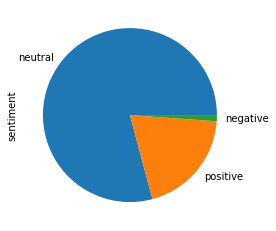
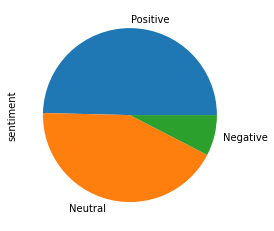
We use the Sentiment Analysis API on our texts and get the sentiment and score of each text. The class with the maximum probability is selected. Have a look at the distribution of each kind of sentiment (Note: We club ‘mixed' and ‘neutral' score together into ‘neutral' score)
Connect to Text Analytics API
The Text Analytics API is a suite of text analytics web services built with best-in-class Microsoft machine learning algorithms. The API can be used to analyze unstructured text for tasks such as sentiment analysis, key phrase extraction and language detection. No training data is needed to use this API; just bring your text data. This API uses advanced natural language processing techniques to deliver best in class predictions.
Further documentation can be found in https://docs.microsoft.com/en-us/azure/cognitive-services/text-analytics/overview
Detect sentiment in the text
Sentiment API returns the overall sentiment of a text (Positive, Negative, Neutral). It returns the probability for each class which adds up to 1. This is an example response from the API.
{
"text": "Hello world.",
"sentiment": "neutral",
"confidenceScores": {
"positive": 0.07,
"neutral": 0.91,
"negative": 0.02
},
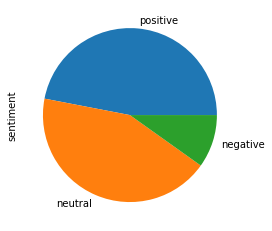
Allocating the sentiment class depends on the sentiment score. Have a look at the distribution of the score and each kind of sentiment :
Connect to Cloud Natural Language API
Google Cloud Natural Language reveals the structure and meaning of text by offering powerful machine learning models in an easy to use REST API. You can use it to extract information about people, places, events and much more, mentioned in text documents, news articles or blog posts. You can use it to understand sentiment about your product on social media or parse intent from customer conversations happening in a call center or a messaging app. You can analyze text uploaded in your request or integrate with your document storage on Google Cloud Storage.
Detects sentiment in the text
Sentiment Analysis inspects the given text and identifies the prevailing emotional opinion within the text, especially to determine a writer's attitude as positive, negative, or neutral. Sentiment analysis is performed through the analyzeSentiment method. It returns a score and magnitude for each sentence or request.
For information on which languages are supported by the Natural Language API, see Language Support. For information on how to interpret the score and magnitude sentiment values included in the analysis, see Interpreting sentiment analysis values.
We will use this API on our texts and get the sentiment and magnitude of each text.
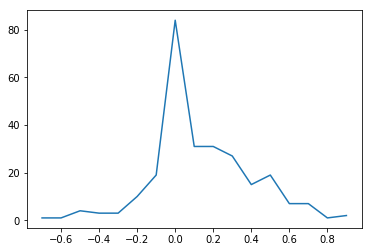
Have a look at the distribution of the score:
Allocating the sentiment class depends on the sentiment score and magnitude.
Criteria | Class |
Score > 0.25 | ‘Positive' |
Score < -0.25 | ‘Negative' |
Otherwise | ‘Neutral' |
The distribution should be like this:
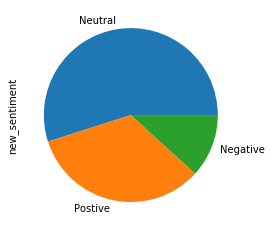
Token based text embedding trained on English Google News 130GB corpus. Can be found here. This is one of the word embedding models that was pre-trained on the google news corpus. It is quite small in size with only about 20 hidden parameters.
Detect Sentiment in Text
The model return 3 probabilities for the each class i.e. Positive, Negative and Neutral. Here is a response example.
The distribution of the sentiments is as follows:
Bidirectional Encoder Representations from Transformers (BERT) is a technique for NLP (Natural Language Processing) pre-training developed by Google. BERT was created and published in 2018 by Jacob Devlin and his colleagues from Google. Google is leveraging BERT to better understand user searches. The original English-language BERT model used two corpora in pre-training: BookCorpus and English Wikipedia. BERT has three concepts embedded in the name.
First, transformers are a neural network layer that learns the human language using self-attention, where a segment of words is compared against itself. The model learns how a given word's meaning is derived from every other word in the segment.
Second, bidirectional means that the recurrent neural networks (RNNs), which treat the words as time-series, look at sentences from both directions. The older algorithms looked at words in a forward direction trying to predict the next word, which ignores the context and information that the words occurring later in the sentence provide. BERT uses self-attention to look at the entire input sentence at one time. Any relationships before or after the word are accounted for.
Finally, an encoder is a component of the encoder-decoder structure. You encode the input language into latent space, and then reverse the process with a decoder trained to re-create a different language. This is great for translation, as self-attention helps resolve the many differences that a language has in expressing the same ideas, such as the number of words or sentence structure.
In BERT, you just take the encoding idea to create that latent representation of the input, but then use that as a feature input into several, fully connected layers to learn a particular language task.
Detect Sentiment in Text
The model return 3 probabilities for the each class i.e. Positive, Negative and Neutral. Here is a response example.

The distribution of the sentiments is as follows:
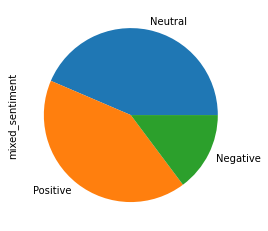
Below is the compared sentiment analysis on Edgar data through different Natural Language API's.
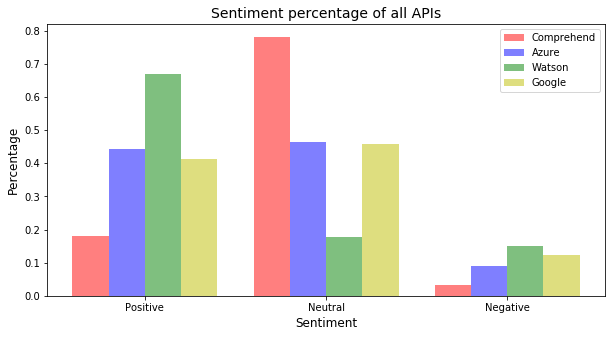
Comprehend
The most positive text given by Comprehend is:
"International spine, particularly in the developed markets is doing well and growing better than it has in recent quarters and we had a positive kyphon quarter and are encouraged by that. When you put all that together, particularly the new product cadence in the US, we think we have a good pathway towards growing the US spine business this fiscal year."
Analysis result on the same text from other APIs:
Azure : positive
Watson : positive
Google : positive
The most negative text given by Comprehend is:
"The Q1 gross margin was 74.1%. After adjusting for a 30 basis point negative impact from foreign currency the Q1 gross margin on a non-GAAP operational basis was 74.4%."
Analysis result on the same text from other APIs:
Azure : negative
Watson : neutral
Google : neutral
Azure
The most positive text given by Azure is:
"Bob Hopkins: Great. Thank you."
Analysis result on the same text from other APIs:
Comprehend : positive
Watson : positive
Google : positive
The most negative text given by Azure is:
"The gross margin continues to include significant spending on additional resources mostly diverted from R&D to address quality issues in neuromodulation and diabetes, which negatively affected the Q1 gross margin by approximately 40 basis points."
Analysis result on the same text from other APIs:
Comprehend : negative
Watson : negative
Google : negative
Google
The most positive text given by Google is:
"Covidien has extensive emerging market R&D and manufacturing while Medtronic has well established clinical expertise. These capabilities applied across a much broader product offering will significantly increase the number of attractive solutions that we can offer to governments and major providers."
Analysis result on the same text from other APIs:
Comprehend : neutral
Azure : positive
Watson : positive
The most negative text given by Google is:
"Reported revenues for our peripheral business declined in the mid single digits in Q1. However, after adjusting for the discontinued product lines just mentioned, our peripheral business grew in the high single digits with strong double digit growth in SFA and DCB products."
Analysis result on the same text from other APIs:
Comprehend : negative
Azure : neutral
Watson : negative
Google NEWS Model
The most positive sentence given by this model is:
"Omar Ishrak: Okay, thanks everyone for all your questions. And we look forward to updating you on our progress on our Q2 call which we anticipate holding on November 18th. With that, and on behalf of our entire management team, I'd like to thank you all again for your continued support and interest in Medtronic. Thank you and have a great day."
The most negative sentence by this model is:
‘The gross margin continues to include significant spending on additional resources mostly diverted from R&D to address quality issues in neuromodulation and diabetes, which negatively affected the Q1 gross margin by approximately 40 basis points.'.
BERT Model
The most positive sentence given by BERT is:
"Matthew Dodds: Thanks, Mike. Thanks, Gary."
Note: The small sentences as this one should be filtered out in the pre-processing step itself.
The most negative sentence given by BERT is:
'This communication is not intended to and does not constitute an offer to sell or the solicitation of an offer to subscribe for or buy or an invitation to purchase or subscribe for any securities or the solicitation of any vote or approval in any jurisdiction pursuant to the acquisition, the merger or otherwise, nor shall there be any sale, issuance or transfer of securities in any jurisdiction in contravention of applicable law. No offer of securities shall be made except by means of a prospectus meeting the requirements of Section 10 of the Securities Act of 1933, as amended.'