Last Updated: 07/19/2021
What is this project?
Modern deep learning approaches have shown promising results in meteorological applications like precipitation nowcasting, synthetic radar generation, front detection, and several others. In order to effectively train and validate these complex algorithms, large and diverse datasets containing high-resolution imagery are required. Petabytes of weather data, such as from the Geostationary Environmental Satellite System (GOES) and the Next-Generation Radar (NEXRAD) system, are available to the public; however, the size and complexity of these datasets is a hindrance to developing and training deep models. To help address this problem, we introduce the Storm EVent ImagRy (SEVIR) dataset - a single, rich dataset that combines spatially and temporally aligned data from multiple sensors, along with baseline implementations of deep learning models and evaluation metrics, to accelerate new algorithmic innovations. SEVIR is an annotated, curated, and a spatiotemporally aligned dataset containing over 10,000 weather events that each consist of 384 km x 384 km image sequences spanning 4 hours of time. Images in SEVIR were sampled and aligned across five different data types: three channels (C02, C09, C13) from the GOES-16 advanced baseline imager, NEXRAD vertically integrated liquid mosaics, and GOES-16 Geostationary Lightning Mapper (GLM) flashes. Many events in SEVIR were selected and matched to the NOAA Storm Events database so that additional descriptive information such as storm impacts and storm descriptions can be linked to the rich imagery provided by the sensors. We describe the data collection methodology and illustrate the applications of this dataset with two examples of deep learning in meteorology: precipitation nowcasting and synthetic weather radar generation. In addition, we also describe a set of metrics that can be used to evaluate the outputs of these models. As of this writing, the SEVIR dataset can be downloaded from https://registry.opendata.aws/sevir/. Baseline implementations of selected applications are also available at https://github.com/MIT-AI-Accelerator/neurips2020-sevir.
Use Case
We use this model to generate new image samples.
What will you build?
- A Pre-trained model for generating synthetic image data.
What will you learn?
- Preprocessing required for the generation of synthetic time series
- How to analyze various generated scenarios
Example Request:
- Prediction from the synthetic radar data by using pre-trained model
POST /synthetic/predict?model_name=mse_vgg_weights&dataset_name=synrad_testing&length=1&access_token=xxxx Host: https://qusynthesize.quantuniversity.com Authorization: xxxxx Content-Type: application/json connection: keep-alive content-length: 3384956 content-type: application/json date: Tue,20 Jul 2021 14:51:52 GMT server: nginx/1.14.0 (Ubuntu) Accept-Charset:utf-8
The definition of request is equal to the regular call to a post above. The response is identical except for adding four additional fields
Fields | Type | Description |
model_name | string | Select the model to make a prediction. For this project, we provide mse_model, mse_vgg_model, and gan model |
dataset_name | string | Select the dataset you want to predict. For this project, we only provide synrad_testing dataset |
length | int | Length of the dataset to train |
token | string | Get the token information for authorization |
There are additional rules around publishing that each request to this API must respect:
- You should get access_token from QuUniversity and use that token to query every APIs it provides. Please the link: https://academy.qusandbox.com
- Carefully choose the length of the dataset to train, it might consume a long time.
Problems errors:
Error code | Description |
400 Bad Request | Required fields were invalid, not specified |
401 Unauthorized | The access_token is invalid or has been revoked |
500 Internal Server Error | Something went wrong on the model side, it will be fixed soon ... |
- Randomly generate new synthetic data
POST /synthetic/random_generate?access_token=xxxx
Host: https://qusynthesize.quantuniversity.com
Authorization: xxxxx
Content-Type: application/json
connection: keep-alive
content-length: 3190084
content-type: application/json
date: Tue,20 Jul 2021 15:12:47 GMT
server: nginx/1.14.0 (Ubuntu)
Accept-Charset:utf-8
Content:
{
"models": [
"mse_weights"
],
"dataset": "synrad_testing",
"length": 1,
"is_random": "true",
"do_inference": "true"
}
The definition of request is equal to the regular call a post above. The response is identical except for adding four additional fields
Fields | Type | Description |
models | list | Select the models to generate new sample data. For this project, we provide mse_weight, mse_vgg_weight, and gan |
dataset_name | string | Select the dataset you want to simulate. For this project, we only provide synrad_testing dataset |
length | int | Length of the dataset to generate |
is_random | bool | Randomly or sequentially choose data from a given dataset and make generation |
do_inference | bool | Whether we should do inference in this generation |
token | string | Get the token information for authorization |
There are additional rules around publishing that each request to this API must respect:
- You should get access_token from QuUniversity and use that token to query every APIs it provides. Please the link: https://academy.qusandbox.com
Problems errors:
Error code | Description |
400 Bad Request | Required fields were invalid, not specified |
401 Unauthorized | The access_token is invalid or has been revoked |
422 Validation Error | The given parameter is invalid, please check the spelling |
500 Internal Server Error | Something went wrong on the model side, it will be fixed soon ... |
- Prediction from the synthetic radar data by using a pre-trained model
POST /synthetic/nowcast?access_token=xxx
Host: https://qusynthesize.quantuniversity.com
Authorization: xxxxx
Content-Type: application/json
connection: keep-alive
content-length: 36221687
content-type: application/json
date: Tue,20 Jul 2021 15:42:09 GMT
server: nginx/1.14.0 (Ubuntu)
Accept-Charset:utf-8
Content:
{
"spot": 1,
"models": [
"mse_model"
]
}
The definition of request is equal to the regular call to a post above. The response is identical except for adding four additional fields
Fields | Type | Description |
models | list | Select the models to generate new sample data. For this project, we provide mse_model, style model, mse_and_style model, and gan generator |
spot | int | Select the length to make a prediction |
token | string | Get the token information for authorization |
There are additional rules around publishing that each request to this API must respect:
- You should get access_token from QuUniversity and use that token to query every APIs it provides. Please the link: https://academy.qusandbox.com
- Carefully select the spot, it might take a long time to get the result.
Problems errors:
Error code | Description |
400 Bad Request | Required fields were invalid, not specified |
401 Unauthorized | The access_token is invalid or has been revoked |
422 Validation Error | The given parameter is invalid, please check the spelling |
500 Internal Server Error | Something went wrong on the model side, it will be fixed soon ... |
- Display the real data
|
|
Real Data Sample Images
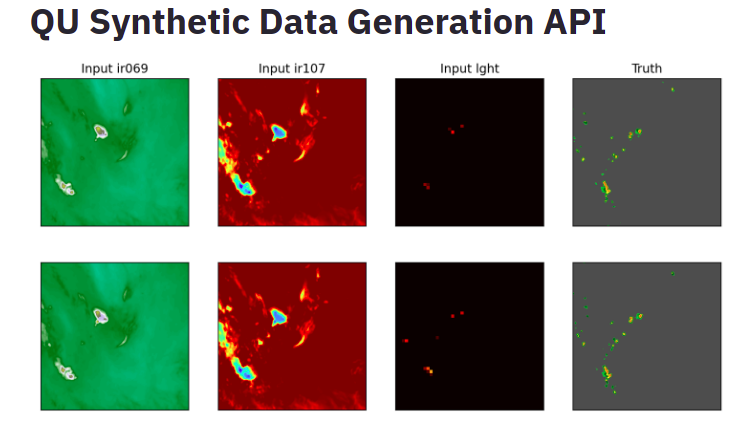
These images use different aspects to display the data. It contains ir069, ir107, ight, and the truth plot to represent the data from real data.
- Synthesize new sample images
|
|
Synthesize the new sample images with different models
- MSE_weights

- MSE_VGG_weights
- GAN_MAE_weights
The fifth image is generated by using the corresponding model with the sequential sub dataset. You can choose randomly choose the sub dataset to generate a new sample image, it should look differently.
- Get predictions by using Nowcast
|
|
Make predictions with different models in Nowcast
